A few months back, I worked through VictoriaMetrics’ Go concurrency series and wanted to get some practice. So I implemented a few distributed systems, work distribution patterns to see how the concurrency patterns translate.
Work distribution is fundamental to building scalable systems - you need ways to spread processing across multiple components while coordinating the results. Go’s goroutines and channels map well to distributed system concepts - channels as service communication, goroutines as system components, WaitGroups for coordination. Here’s what I learned.
Producer-Consumer: Async Work Distribution
Producers generate work and send it through channels while consumers process it asynchronously.
type ConsumerResult struct {
ConsumerID int
Data string
}
// start multiple consumers
for id := 0; id < numConsumers; id++ {
wg.Add(1)
go func(consumerID int) {
defer wg.Done()
for msg := range msgChan {
result := ConsumerResult{
ConsumerID: consumerID,
Data: fmt.Sprintf("processed-%d", msg),
}
resultChan <- result
}
}(id)
}
// start a single producer that sends work into a channel
go func() {
defer close(msgChan)
for i := 1; i <= 25; i++ {
msgChan <- i
}
}()
Buffered channels give you throttling - if consumers can’t keep up, the producer blocks instead of consuming memory.
Use this pattern for event streaming, async processing, or decoupling generation speed from processing speed. It maps directly to Kafka or microservice event handling.
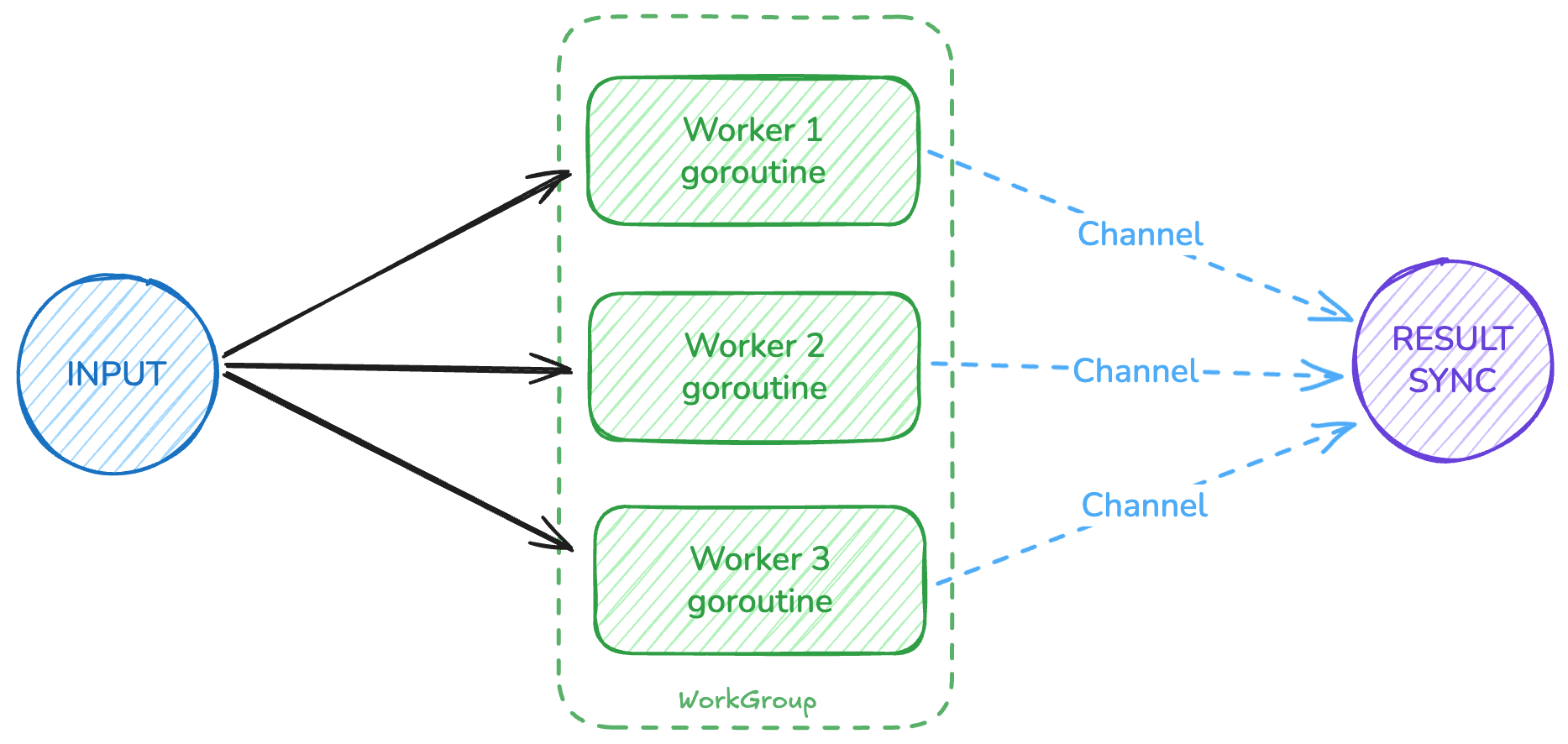
Worker Pools: Controlled Work Distribution
Worker pools give you structure - fixed number of workers pulling from the same job queue. It’s like running N service instances behind a load balancer.
type PoolJob struct {
ID int
Data string
}
// start a fixed number of workers
for i := 0; i < numWorkers; i++ {
wg.Add(1)
go func(workerID int) {
defer wg.Done()
for job := range jobChan {
// do some work
time.Sleep(100 * time.Millisecond)
results <- PoolResult{
WorkerID: workerID,
JobID: job.ID,
Value: fmt.Sprintf("processed-%s", job.Data),
}
}
}(i)
}
The job channel acts like a load balancer - work goes to whichever worker is available.
This pattern is good for CPU-heavy tasks or when you need predictable resource usage. It’s similar to scaling microservice instances for ingress traffic.
Batch Processing: Efficient Work Distribution
Sometimes you need to group items into batches for efficiency or to respect downstream rate limits. This example handles batching by size and by time.
func (p *BatchProcessor) startBatchAggregator() {
go func() {
batch := make([]int, 0, p.batchSize)
flushTimer := time.NewTimer(2 * time.Second)
sendBatch := func() {
<-p.rateLimiter.C // wait for rate limiter
batchCopy := make([]int, len(batch))
copy(batchCopy, batch)
p.batchChan <- batchCopy
batch = batch[:0]
}
for {
select {
case item, ok := <-p.itemChan:
if !ok {
if len(batch) > 0 {
sendBatch()
}
close(p.batchChan)
return
}
batch = append(batch, item)
if len(batch) >= p.batchSize {
sendBatch()
}
case <-flushTimer.C:
if len(batch) > 0 {
sendBatch()
}
}
}
}()
}
The select with the flush timer gives you batches when they’re full OR when time runs out. The rate limiter prevents overwhelming the batch processor and its external dependencies. I used a simple timer here, but you can replace it with much more sophisticated limiting logic as needed.
The batch processing pattern works well for database bulk operations, API integrations with rate limits, or protecting downstream services.
A Few Notes
Working through these patterns reinforced a few things:
- Channels behave like message queues with capacity limits and natural flow control.
- Multiple goroutines running the same function is basically horizontal scaling - same patterns you’d use for scaling system components.
- These patterns compose well. Producer-consumer provides the foundation, worker pools add structure, batching adds efficiency.
| Pattern | Analogy | Use Case |
|---|---|---|
| Producer-Consumer | Message queues, event streams | Event-driven architectures, async processing |
| Worker Pools | Load-balanced system components | Controlled concurrency, predictable resources |
| Batch Processing | ETL pipelines, bulk APIs | Rate limiting, bulk operations |
Error Handling
Error handling in concurrent code needs to be explicit and planned upfront, similar to how distributed systems need circuit breakers and retry logic. I used result structs that carry either data or errors:
type WorkResult struct {
Data string
Err error
}
func worker(jobs <-chan int, results chan<- WorkResult) {
for job := range jobs {
if job%7 == 0 { // simulate some failures
results <- WorkResult{Err: fmt.Errorf("job %d failed", job)}
continue
}
results <- WorkResult{Data: fmt.Sprintf("processed-%d", job)}
}
}
For timeouts and cancellation, context.Context works well:
func workerWithTimeout(ctx context.Context, jobs <-chan int, results chan<- WorkResult) {
for {
select {
case job := <-jobs:
// process the job
case <-ctx.Done():
results <- WorkResult{Err: ctx.Err()}
return
}
}
}
Beyond the basics
These patterns scratch the surface of Go’s concurrency toolkit. The VictoriaMetrics series I mentioned dives deep into more advanced primitives like sync.Mutex for protecting shared state, sync.Pool for object reuse, sync.Once for one-time initialization, and sync.Map for concurrent map access. I recommend checking it out if you haven’t already!
I intentionally stuck to channels and WaitGroups in my examples here - they mirror message passing between services naturally and keep the code readable. Once those patterns are solid, adding mutexes and other synchronization primitives becomes intuitive because you already understand the coordination challenges.
As you build more complex systems, you’ll need these other tools. Mutexes become your distributed locks, sync.Pool mirrors connection pooling in microservices, sync.Once handles singleton initialization across service instances (similar to leader election), and sync.Map acts like shared caches that multiple services access concurrently.
Next: circuit breaker and fan-in/fan-out implementations.